Sie kann in kürzester Zeit exorbitante Datenmengen verarbeiten und mag bisweilen bedrohlich wirken. Doch während Künstlicher Intelligenz großes Potenzial in der Medizin zugeschrieben wird, sollte die Endentscheidung in der Hand der Mediziner bleiben, meint der Forscher David Major vom Zentrum für Virtual Reality und Visualisierung (VRVis), der im Hintergrund artifizieller Netze die Fäden zieht.
Claudia Tschabuschnig
„Es gibt immer Grenzfälle, bei denen Computersysteme an der Kippe stehen.“
Es mag verheißungsvoll klingen: eine Diagnose, die automatisiert in Windeseile gestellt ist. Gerade in der Radiologie sollen künstliche Maschinen all ihre Stärken ausspielen. Demgegenüber stehen das Blackbox-Problem, fehlende medizinische Daten und diagnostische Grenzfälle. Was es damit auf sich hat, erklärt Major, der an der zukunftsträchtigen Technologie, die Radiologen in ihrer täglichen Arbeit unterstützen soll, werkt.
medinlive: Rund um künstliche Intelligenz gibt es unzählige Begrifflichkeiten. Was sind künstliche, neuronale Netzwerke? Und wofür steht der Begriff Deep Learning?
Major: Mit künstlichen neuronalen Netzen können verschiedene Problemstellungen computerbasiert gelöst werden. Sie sind inspiriert vom menschlichen Gehirn und lassen sich für maschinelles Lernen und Künstliche Intelligenz einsetzen. Sie bestehen, ähnlich wie unser Gehirn, aus Neuronen, die miteinander verbunden sind, mathematische Operationen ausführen und Information weiterleiten. Deep Learning (mehrschichtiges Lernen oder tiefgehendes Lernen, Anm.) ist eine Methode des maschinellen Lernens, die neuronale Netze für die Problemlösung anwendet und ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung (Näheres zur Funktionsweise neuronaler Netze siehe Infokasten unten). Während bei früheren, konventionellen Methoden Muster oder Merkmale, auf die man achten will, manuell und oft mit Expertenwissen definiert werden mussten, passiert das bei Deep Learning automatisch in einem KI-Modell. Beispiele für konventionelle Methoden des maschinellen Lernens sind Merkmalsextraktionsverfahren, wie etwa Kennzahlen von Grauwert-Histogrammen oder Grauwertematrizen in Kombination beispielsweise mit einer Support Vector Machine (eine Methode, die Muster in Klassen unterteilt, Anm.) oder Decision Trees (Methoden, die ein Vorhersagemodell in Form von Baumstrukturen lernen und repräsentieren, Anm).
medinlive: Sie arbeiten mit medizinischen Bildern. Wie gehen Sie vor?
Major: Zunächst wählen wir eine Netzwerkarchitektur, entsprechend der Aufgabe, die erfüllt werden soll. Wir verwenden generell Convolutional Neural Networks (CNNs) vom Typ her, da diese Netze für die Bearbeitung von Bildern konzipiert sind. Die Aufgabe kann etwa die Kategorisierung oder Klassifizierung sein (etwa: „krank“-„nicht krank“ oder „nicht krank“ und „welche Erkrankung“) oder die Segmentierung, bei der die Bilder in Bereiche unterteilt werden. Ein Beispiel ist die Kategorisierung von Lungenröntgenbilder in Klassen wie Gesund, Tuberkulose oder Pneumonie. Segmentierung wird etwa bei der Tumorerkennung angewandt, wobei der Tumor umrandet, seine Größe ermittelt und über die Zeit weiterverfolgt wird. Diese zwei Methoden machen einen Großteil dessen aus, womit in der medizinischen Anwendung von KI gearbeitet wird. Mit Hilfe von Beispieldaten wird das Netzwerk trainiert, dabei geht es vor allem um die Optimierung, also Fehlerminimierung, aber auch um die richtige Vorbereitung und Zusammensetzung der Trainingsdaten. Eine wichtige Vorraussetzung für die Fehlerminimierung ist, dass die Beispielbilder mit der richtigen Diagnose gekennzeichnet sind. So kann der Fehler zwischen dem Output des KI-Modells und der richtigen Diagnose der Bilder gemessen werden. Das nennt man überwachtes Lernen.
medinlive: Ist es für Sie noch nachvollziehbar, wie das Modell zu dem Ergebnis kommt, oder stellt es eine Blackbox dar?
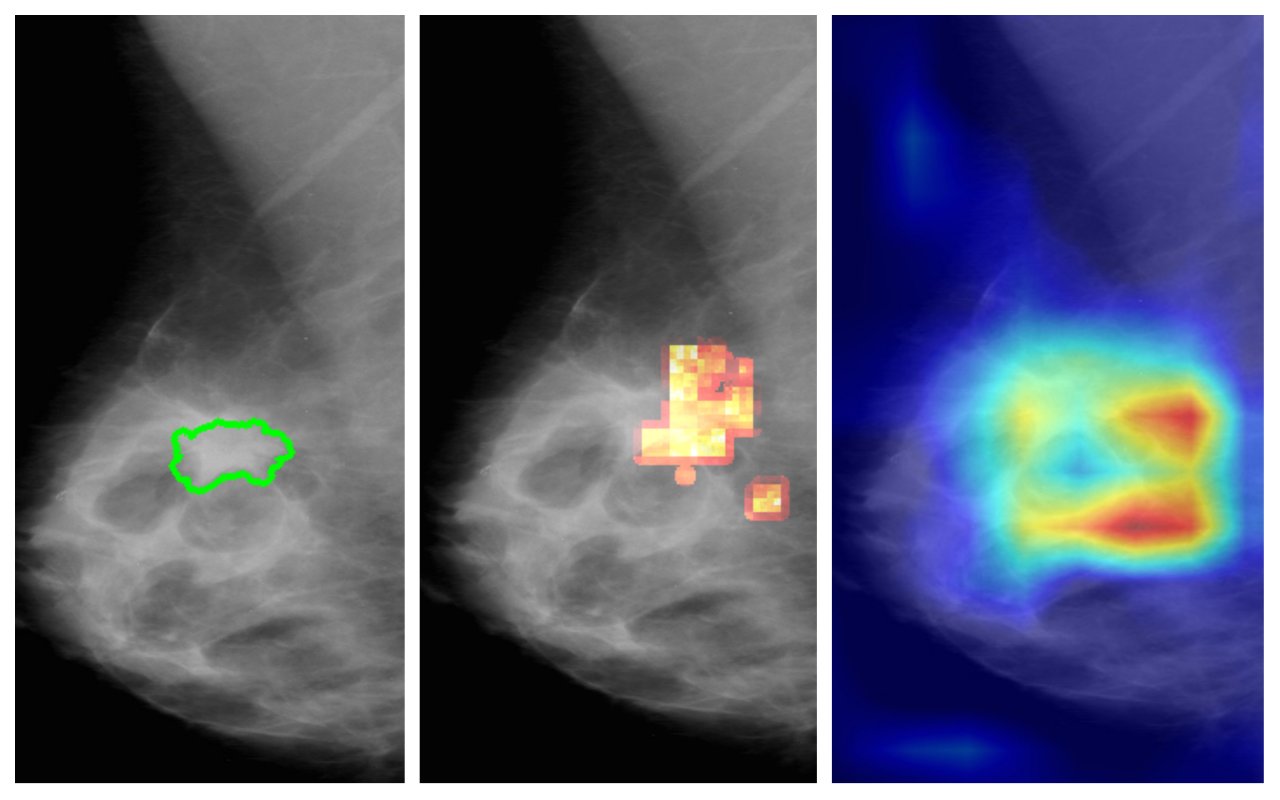
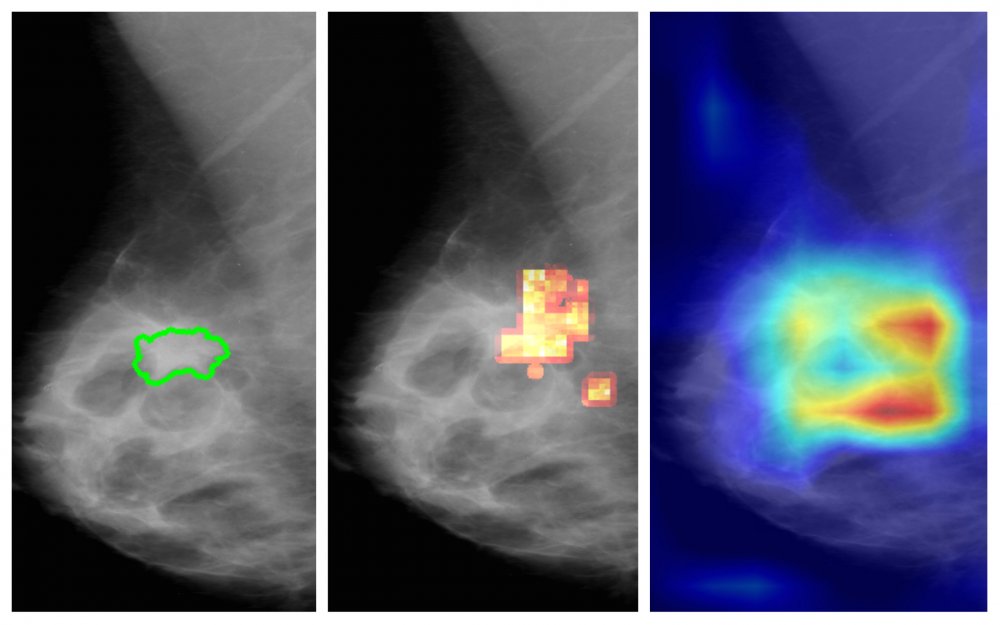
Major: Das Ergebnis ist für uns schwer nachzuvollziehen, denn so ein Netzwerk besteht aus vielen Bausteinen. In einer meiner letzten Forschungsarbeiten ging es darum den Entscheidungsprozess eines KI-Modells zu verstehen. Dieses Modell traf die Annotation „krank“-„nicht krank“. Wir wollten dabei herausfinden, welche Stelle auf einem medizinischen Bild ausschlaggebend war für die Entscheidung des Netzwerks. Das wird oft mittels Heat Maps (ähnlich einem Wärmebild, Anm.) visualisiert. Bestehende Methoden haben im Kontext medizinischer Daten allerdings keine zuverlässigen Ergebnisse geliefert. Diese Lücke konnte mit der von uns entwickelten Methode jetzt geschlossen werden.
Visualiserungsmethode für die Ermittlung ausschlaggebender Bildbereiche eines KI-Modells: (a) Original mit annotiertem Befund, (b) Heat Map der Methode von VRVis, (c) Heat Map einer branchenüblichen Lösung (GradCAM).
medinlive: Gibt es Ähnlichkeiten bei der Funktionsweise des menschlichen Gehirns und künstlichen Netzwerken?
Major: Dazu gibt es unterschiedliche Meinungen. Das menschliche Gehirn ist jedenfalls viel komplexer. Die Netzwerke, also Neuronen und deren Verbindung sind, meiner Ansicht nach, die einzige Ähnlichkeit. Es wird vermutet, dass die hierarchische Verarbeitung von Informationen in einem neuronalen Netz die der Sehrinde ähnelt. Die heute verwendeten künstlichen Netze funktionieren gut für sehr spezielle, klar definierte Aufgaben. Man kann nicht so leicht ein selbstlernendes Modell, das universell einsetzbar ist und selber Entscheidungen trifft, erschaffen. Selbst wenn KI-Modelle besser werden, in der Radiologie muss der Arzt oder die Ärztin das letzte Wort haben.
medinlive: Warum?
Major: Für die Endentscheidung in der Medizin braucht man viel komplexeres Wissen und damit alles, was Menschen gut können, wie beispielsweise Entscheidungsfindung bei komplexen Problemstellungen in denen viele Faktoren eine Rolle spielen können. Heutige Netzwerke können diese Komplexität im medizinischen Kontext noch nicht mit der nötigen Präzision wiederspiegeln. Ein anderer Schwachpunkt betrifft die Varianz. Das menschliche Gehirn kann noch besser Wissen übertragen, also Objekte auch aus anderen Perspektiven erkennen. Das können künstliche Systeme nicht so gut. Es gibt immer medizinische Grenzfälle, bei denen Computersysteme an der Kippe stehen. Deswegen braucht man Ärztinnen und Ärzte für eine Endentscheidung. In manchen Fällen muss man etwa auf eine Biopsie zurückgreifen. Maschinen machen viele Fehler und können häufig nicht optimal trainiert werden. Einerseits, weil sie nicht so viele Daten sehen und so viel Wissen aufsaugen können wie ein Radiologe. Sehr oft werden diese Modelle mit einem kleinen Datensatz trainiert, in dem immer auch ein Bias (eine Verzerrung, Anm.) enthalten ist. Andererseits gibt es bei der Gesichtserkennung auch das Problem, dass es zu viele Daten von Gesichtern mit heller Hautfarbe gibt, was zu Verzerrung und Diskriminierung führt. Diese Debatte ist noch nicht gelöst. Vor allem bei medizinischen Daten gibt es darüber hinaus Hindernisse in der Beschaffung. Durch das Inkrafttreten der Datenschutz-Grundverordnung ist es noch schwieriger geworden diese Daten zu bekommen. Es wäre auch interessant, den Zugriff auf die Follow-up-Daten zu haben, um das Wachstum und Veränderungen einer Krankheit beobachten zu können.
medinlive: Gibt es grundsätzlich Bestrebungen Bilder auch öffentlich mehreren Forschern zur Verfügung zu stellen?
Major: Es gibt öffentlich zugängliche Datensätze (wie zB. das Cancer Imaging Archive), die etwa im Rahmen von Wettbewerben zur Verfügung gestellt werden. An denen können Forschungsgruppen arbeiten, was auch gut funktioniert. Wie man leichter an medizinische Daten kommt, ist leider noch nicht gelöst. Darüber hinaus könnte man mit Diagnosezentren arbeiten und ein Projekt hochziehen.
medinlive.: Dann gibt es noch die Möglichkeit, Daten künstlich herzustellen mittels Generative Adversarial Networks (GAN)(„erzeugende generische Netzwerke“, die aus zwei künstlichen neuronalen Netzwerken bestehen, die ein Nullsummenspiel durchführen, Anm.). Ist das auch ein Thema?
Major: Das ist ein Thema, aber sehr heikel, denn inwieweit ein maschinell generiertes Bild wirklich die anatomischen Gegebenheiten und Pathologie korrekt wiedergibt, ist fraglich. Solche Themen sollten eng mit Ärztinnen und Ärzten analysiert werden. Diese Methode könnte aber etwa aktuell dabei helfen neue Medikamente zu entwickeln.
medinlive: Welche Fragen haben Sie an Radiologen?
Major: Für uns ist wichtig zu sehen, wie Ärztinnen und Ärzte die Problemstellung oder Aufgabenstellung angehen. Forscher brauchen nämlich die Kennzeichnung der Bilder mit der richtigen Diagnose, dieser Input muss von Radiologen kommen. Wenn wir nicht genügend Annotationen erhalten, können wir kein gutes Modell erstellen. Deep Learning ist sehr datenhungrig. Man braucht viele Daten, damit am Ende ein gut funktionierendes Modell steht, das mit zukünftigen Daten arbeiten kann. Es gibt immer mehr Radiotechnologen, die auch Wissen in Richtung Künstlicher Intelligenz haben. Dieser Trend kann helfen, um die Zusammenarbeit zwischen uns und Radiologen zu fördern.
medinlive: Welche Methoden verwenden Sie derzeit, um die Ergebnisse zu evaluieren?
Major: Es gibt unterschiedliche Methoden. Die Genauigkeitsprüfung (accuracy evaluation, Anm.) ist beispielswiese eine solche Maßzahl, die angibt, wie viele Bilder am Ende richtig zugeordnet wurden. Dafür nehmen wir die Annotation der Radiologen. Grundsätzlich läuft es so ab, dass wir die Daten in Trainingsdaten, Beurteilungsdaten und Testdaten unterteilen. Mit Trainingsdaten lernt das Modell. Mit den Beurteilungsdaten werden Parameter eingestellt, etwa wie lange das Training dauert. Stellt man fest, dass der Fehler auf den Beurteilungsdaten nicht weiter minimiert werden kann, wird das Training gestoppt . Ausserdem gibt es noch die Testdaten, die man in dem ganzen Prozess nicht berühren soll. Sie stehen für die zukünftigen Daten, also die Daten, die man auch in der Praxis sehen könnte. Grundsätzlich sind dies alles unterschiedlichen Daten von unterschiedlichen Patienten, aber vom gleichen Typ, den dann auch das trainierte Netzwerk verarbeiten bzw. beurteilen soll.
medinlive: Künstliche Intelligenz wird oft mit Zeitoptimierung in Verbindung gebracht. Wie lange dauert der Prozess davor - der Trainingsprozess - im Durchschnitt?
Major: Das hängt von der Aufgabenstellung, der Menge der Daten und den technischen Ressourcen ab. Der Grund warum sich Deep Learning-Modelle durchgesetzt haben, liegt darin, dass die Grafikkarten kontinuierlich optimiert wurden. Das Training des Modells kann Stunden bis Tage dauern. Mit weniger Daten braucht man etwa drei bis fünf Stunden, aber bei hunderten, tausenden oder Millionen Daten würde es Tage brauchen. Würde man allerdings stärkere Grafikkarten, wie etwa Googles Tensor Processing Units (TPU), hernehmen, könnte man mit Millionen von Datensätzen auch innerhalb von Stunden trainieren.
medinlive: Was ist wichtig beim Einsatz von KI-Modellen in der Arztpraxis?
Major: Am wichtigsten ist es meiner Ansicht nach, diese Technologien an der richtigen Stelle des klinischen Alltags einzusetzen, was derzeit nicht immer geschieht. Dieses Thema wurde zuletzt auch bei der Radiologiekonferenz ECR in Wien diskutiert. Grundsätzlich müsste man Radiologen fragen, an welchen Stellen sie Unterstützung oder Automatisierung brauchen, um die Effizienz, Effektivität und all diese Faktoren zu erhöhen. Wenn man beispielsweise beim Lungentumor-Screening auf einem Scan einen Knoten erkennt, umrandet man diesen, misst ihn ab und macht sich Notizen dazu. Die Frage ist, was man tun kann, um dies schneller ablaufen zu lassen. Ein KI-Modell könnte diese Umrandung besser machen als ein Mensch, der Arzt oder die Ärztin sie dann kontrollieren und bei Bedarf korrigieren. Ein weiteres Potenzial weist der Dokumentationsprozess auf, das man ebenso strukturieren und automatisieren kann.
Die Architektur der KI-Modelle. Wie funktionieren künstliche, neuronale Netzwerke?
Die Theorie der neuronalen Netze hat ihren Ursprung in den 50er-Jahren. 1958 publizierte Frank Rosenblatt das Perzeptron-Modell (nach engl. perception, „Wahrnehmung“) das bis heute die Grundlage künstlicher neuronaler Netze darstellt. Es ist eine klassische Lösung, wie Relationen und Beziehungen kodiert und erkannt werden. Im Prinzip ist das ein vereinfachtes künstliches neuronales Netz, das in der Grundversion aus einem einzelnen künstlichen Neuron mit anpassbaren Gewichtungen und einem Schwellenwert besteht. Ein Neuron ist mit mehreren Inputs verknüpft und erzeugt einen binären Output. Die Verbindungen zwischen den Inputs und dem Neuron werden gewichtet je nach Relevanz der Inputeinheiten. Der binäre Output entsteht durch den Aktivierungsvorgang, wobei es überprüft wird, ob die gewichtete Summe der Inputs einen bestimmten Schwellenwert überschreitet.
Eine Sammlung an Neuronen bildet einen „Layer“ und mehrere solche „Layer“ ergeben zusammengeschaltet ein tiefes künstliches neuronales Netz.
Ein spezieller und populärer Typ von neuronalen Netzen sind Convolutional Neural Networks (CNNs), die sich insbesondere für die visuelle Erkennung von Objekten in Bildern und Videos eignen. Wie der Namensteil Convolutional (deutsch: faltend) andeutet, gehört zu der Art, wie die Netze aufgebaut sind, eine mathematische Operation, die als Faltung bezeichnet wird. Bei der Faltung werden Bildbereiche mit einem Faltungskernel oder Filter multipliziert und die Produktterme addiert. Ein Beispiel für einen Filter ist der Kantenfilter. Das Ziel ist beim Lernvorgang Filtermuster zu lernen die Aspekte des Bildes betonen die für den jeweiligen Task ausschlaggebend sind. Neben den Faltungen gibt es in einem gewöhnlichen CNN auch sogenannte Pooling-Operationen. Diese verkleinern das Bild, im einfachsten Fall werden die Breite und Höhe jeweils halbiert, indem aus jeweils 2×2 Pixeln der Maximalwert genommen wird. Das Ziel der Verkleinerung ist strukturelle Zusammenhänge in dem Bild deutlicher zu machen. In einer typischen Architektur eines gewöhnlichen CNNs wiederholen sich Faltungsschichten mit anschließenden Pooling-Schichten mehrfach. Die Zwischenbilder, die durch Anwendung von Faltung und Pooling entstehen heißen Feature-Maps (deutsch: Merkmalsabbildungen). Die ersten Layers aktivieren typischer weise kantenähnliche Merkmale, die Mittleren Konzepte wie etwa Räder, Fenster und die letzten Layer erkennen Merkmale die für die Endklassifikation eines Bildes wie in einem Auto oder Haus ausschlaggebend sind wenn man CNNs auf Fotos anwendet.
Das Prinzip des Perzeptron ist jenes, auf dem künstliche Systeme beruhen. Der Unterschied zwischen künstlichen und natürlichen Systemen ist dem Hirnforscher Wolf Singer zufolge zudem die Reziprozität der Verbindungen. Denn bei künstlichen Systemen geht der Informationsfluss nur in eine Richtung, wohingegen sich bei der Untersuchung von Gehirnen von Makaken zeigt, dass zwischen den Hirnarealen hunderttausende Nervenfasern liegen, die in tausende Richtungen gehen und ein dicht vernetztes System bilden.
Seit 2000 wird der BegriffDeep Learning vorwiegend im Zusammenhang mit künstlichen neuronalen Netzen verwendet.
Das Zentrum für Virtual Reality und Visualisierung (VRVis) ist das größte unabhängige Forschungszentrum im Bereich Visual Computing (Bildinformatik oder Grafische Datenverarbeitung) in Österreich und betreibt mit seinen über 70 Mitarbeiterinnen und Mitarbeitern in Zusammenarbeit mit Industrieunternehmen und Universitäten innovative Forschungs- und Entwicklungsprojekte. www.vrvis.at Das VRVis ist eines der COMET-Kompetenzzentren der Stufe K1 und gehört damit zusammen mit den COMET-Kompetenzzentren der Spitzenstufe K2 zu den vom Bund geförderten Zentren der österreichischen Technologiepolitik.
David Major ist Forscher in der Biomededical Image Informatics-Forschungsgruppe bei VRVis, dem Zentrum für Virtual Reality und Visualisierung. In seinen Forschungsarbeiten beschäftigt sich Major mit der Anwendung von KI-Modellen zur Bildanalyse in der Radiologie.
David Major is a researcher in the Biomedical Image Informatics research group at VRVis(Center for Virtual Reality and Visualization). His research focuses on the application of AI models for image analysis in radiology.
VRVis
„Deep Learning ist sehr datenhungrig. Man braucht viele Daten, damit am Ende ein gut funktionierendes Modell steht, das mit zukünftigen Daten arbeiten kann.“
Visualiserungsmethode für die Ermittlung ausschlaggebender Bildbereiche eines KI-Modells: (a) Original mit annotiertem Befund, (b) Heat Map unserer Methode , (c) Heat Map einer branchenüblichen Lösung (GradCAM).